Overview
This document is an introduction to EasyExtend, a system for creating
extension languages for Python. It provides a broad system
vision and argues a lot why
things are how they are. It is more a whitepaper than a manual. It has
many intersections with the tutorial
but it does not guide the reader consistently through a single
exhaustive example but spots several themes separately. In order to
understand and use EasyExtend you possibly need to read both.
What is EasyExtend?
Preprocessor generator for Python
EasyExtend (EE) is a preprocessor generator and
metaprogramming framework written in pure Python and integrated with
CPython. The main purpose of EasyExtend is the creation of extension
languages i.e. adding custom syntax and semantics to Python. EasyExtend
comes out of the box as a single package with no dependecies other
than those to Pythons standard library.
Parser generator
EasyExtend provides a powerful parser generator
for top down parsers called Trail.
Trail parsers are trace based,
non-backtracking parsers with one token of lookahead but the capability
of an LL(k) parsers for arbitary k. Trails nondeterministic finite
automata (NFAs) are
used for multiple tasks: most obviously for parsing but also for
lexical analysis, parse tree validation and generation
of parse tree builders.
Blank slate programming languages
Besides
the main goal of providing a system for generating extensions
languages,
EasyExtend can also be used to build languages from the scratch
targeting Pythons virtual machine.
Source inspection and manipulation
EasyExtend provides csttools
which is a library for inspection, modification and synthesis
of parse trees.
Source tree overview and installation advices.

About tokenizers, parsers and syntax tree
constructors.

Wildlife habitats of extension languages and
some prefixology.

About the holes in applications with holes.

Simple fare: consoles, debuggers and command line
options

Caveats and prospects.
1. Getting Started
1.1 Installation
EasyExtend is as a Python package distributed using distutils. It will
be installed in
the site-packages
directory of
your Python distribution using a setup.py
script. The EasyExtend package can be downloaded here.
Installing EasyExtend requires typing
-
python setup.py install
in your shell. For Windows you might
use the Windows installer instead.
In EasyExtend 3.0 you will see roughly following source tree:
[site-packages]+-[EasyExtend]+-[langlets]
+- Grammar
+- Token
+-
fs
+-
__init__.py
+-
cst.py
....
+-
[gallery]
+- __init__.py
+- conf.py
+- langlet.py
+- [lexdef]
+- Token
+- Token.ext
+- __init__.py
+- lex_nfa.py
+- lex_symbol.py
+- lex_token.py
+- [parsedef]
+- Grammar
+- Grammar.ext
+- __init__.py
+- parse_nfa.py
+- parse_symbol.py
+- parse_token.py
+- [tests]
+-
[grammar_langlet]
+- [zero]
+- [langlet_template]
+-
[trail]
+-
[util]
1.1.1 psyco
Although EasyExtend does not require 3rd party packages to run it is
strongly recommended to install psyco.
Without the psyco JIT lexing and parsing is three times slower and what is
even worse it affects user experience: so it is notably slower. There
aren't
any additional settings to be made. Just install psyco. EE uses a
decorator called psyco_optimized that returns a psyco.proxy(f) for a
function f if psyco is available, f otherwise.
1.2 First run
Switch to the directory \langlets\gallery
which is subsequent to EasyExtend ( see file-tree above ) and type
python
gallery_main.py
on your prompt ( here as a Windows example ):
C:\...\EasyExtend\langlets\gallery>python
run_gallery.py
__________________________________________________________________________________
Gallery
On Python 2.5.1 (r251:54863, Apr 18 2007, 08:51:08) [MSC v.1310
32 bit (Intel)]
Langlet documentation:
www.langlet-space.de/EasyExtend/doc/gallery/gallery.html
__________________________________________________________________________________
gal> a = 1
gal> switch a:
.... case 0:
....
print "nok"
.... case 1:
....
print "ok"
....
ok
gal> quit
__________________________________________________________________________________
|
Running tests shall yield
EasyExtend\langlets\gallery>python
run_gallery.py tests\test_gallery.gal
----------------------------------------------------------------------
test_chainlet (test.test_gallery.TestGallery) ... ok
test_importer (test.test_gallery.TestGallery) ... ok
test_mixed (test.test_gallery.TestGallery) ... ok
test_on_stmt_1 (test.test_gallery.TestGallery) ... ok
test_on_stmt_2 (test.test_gallery.TestGallery) ... ok
test_repeat_until_1 (test.test_gallery.TestGallery) ... ok
test_repeat_until_2 (test.test_gallery.TestGallery) ... ok
----------------------------------------------------------------------
Ran 7 tests in 0.000s
OK
|
1.3 Organization
The /EasyExtend root directory contains
all relevant framework modules ( eetokenizer.py, eegrammar.py etc. )
with the exception of the Trail parser generator that has an own
directory. It also contains generic grammar definitions in files like
Grammar and Token.
Languages created with EasyExtend are called langlets.
When a new langlet is
created a subdirectory of EasyExtend/langlets
will be allocated.
Mandatory files of a langlet are
- a conf.py
file containing langlet specific definitions and module imports
- a langlet.py
file containing user defined objects
- a
run_<langletname>.py
file as an entry point.
- a parsedef
directory containing symbols and automata definitions used by Trail for
parsing.
- a
parsedef
directory containing symbols and automata definitions used by Trail for
lexing.
1.4 Learning EasyExtend
The best way to start doing something useful with EasyExtend might be
reading the EasyExtend tutorial
and work through the hex_langlet
creation process and then coming back to this document that sheds more
light on many ideas presented there.
2. Grammars and CSTs
2.1 Grammar and Token
EasyExtend is grammar based. All grammars being used are EBNF
style
grammars. Actually two grammar files are used for each langlet -
one for
the lexically analysis process and one for parsing token streams. They
have the same structure but slightly different semantics ( see Lexing
and Parsing in EasyExtend ). The files accordingly are called Token
and Grammar.
You find them in the root directory /EasyExtend.
These files are
also called basic or fundamental grammars. The Grammar
file specifically is an unmodified copy of Pythons grammar which is
shipped with Pythons source distribution. So EasyExtend for version 2.5
will contain the Grammar file for Python 2.5. It can't be used with
other versions of Python. The notation used to express grammar rules in
EBNF style is inherited from the notation of Pythons Grammar.
2.1.1 Extending
grammars
Syntax
extensions in langlets are based on extending grammars. Each langlet
contains a file called Grammar.ext and a file called Token.ext. You can
overwrite existing rules defined in the fundamental grammar files or
add new rules. Actually each new grammar rule in Grammar.ext or
Token.ext will also lead to the modification of an existing rule
because only this will connect the new rule to the grammar.
Example:
Fundamental Grammar
-------------------
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
compound_stmt: if_stmt | while_stmt | ... |
classdef | with_stmt
... |
Now define a few new rules in the gallery langlet.
Grammar.ext of gallery langlet
------------------------------
compound_stmt: if_stmt | while_stmt | ... |
classdef | with_stmt | repeat_stmt
repeat_stmt:
'repeat' ':' suite 'until' ':' (NEWLINE INDENT test NEWLINE DEDENT |
test NEWLINE )
...
|
The modifications are local
which means they affect the parsing process of gallery but nothing
else. You can reuse the Grammar.ext file of gallery of course and
modify the rules in your own langlet.
2.1.2
Grammars and Node Ids
The sequence in which rules are ordered in the Grammar file determines
the rule ids or node ids of
the grammar rules. A node id
is a numerical value used to refer to a rule in the grammar. You can
find those node ids listed in Python standard library modules like symbol.py
and token.py.
Practically node ids are identifiers of nodes in parse trees. When you
import the stdlib parser module, parse an expression and apply tolist()
on the resulting parser.st
object you will
notice the parse tree in a nested list form containing node ids of the
grammar rules.
>>> import parser
>>> parser.expr("q").tolist()
[258,
[326, [303, [304, [305, [306, [307, [309, [310, [311, [312, [313, [314,
[315, [316, [317, [1, 'q']]]]]]]]]]]]]]]], [4, ''], [0, '']]
>>> |
Those parse trees are called CSTs ( Concrete
Syntax Trees
). CSTs always reflect the grammar structure and the rules which are
used while parsing. CSTs are long, verbose and ugly; they express
operator precedence encoded in the grammar structure; they store
lexical content like parens and punctuations; they make it sometimes
non-obvious to reconstruct the expression structure.
2.1.3 ASTs? YAGNI
!
The EE tutorial provides an
in depth study of the creation process of a specific langlet called the
hex_langlet.
Suppose
you parse source of the hex_langlet and the parser yields a CSTHex.
You can transform the CSTHex into an ASTHex (
Abstract Syntax Tree
) first which has all the good properties of an accessible syntax tree
notation. But the AST is not your target object! The target is either
a CSTPy or an ASTPy. So transforming CSTHex
-> ASTHex
would just an intermediate step for simplifying the transformation of
ASTHex ->
ASTPy.
In
a sense EasyExtend states the hypothesis that ASTs despite being nice
are mostly superflous: you ain't gonna need it. Instead EasyExtend
suggests that powerful API functions operating on CSTs mimicking AST
like access as well as search functions for CST nodes are sufficient.
They might even be better for some purposes because you often want to
do some roundtrips: create a parse tree from source and creating source
from a parse tree. You can store lexical content together with AST
nodes but then transformations preserving lexical structures becomes
more difficult. To put it short: EasyExtend moves the abstraction into
an API and not a datastructure.
2.1.4 The order
of rules
A fundamental grammar can have more than one top level or start
rules.
In case of Grammar those rules are
- file_input
- this rule is
used to parse all files. They can parse the most general forms of
Python statements and expressions.
- single_input
- this rule can be used to parse a
single statement or expression.
- eval_input
- this rule can be used to
parse a comma separated list of expressions.
These rules can be found at the top of the rule definition section. The
node ids assigned in Pythons case are 256, 267 and 258.
The Token file has only one top level rule called token_input.
Unlike the top level rules of Grammar the node id is somewhat rule
squeezed into the middle of the file. The reason is that
Token is an afterthought. Unlike Grammar there is no corresponding
Token file in the Python distribution and the sequence of terminal
nodes ENDMARKER,
NAME, NUMBER,
etc. in Token are important in preserving compliency with node id
sequences for token in Python ( see <root-python>/lib/token.py
).
2.2 CSTs
CSTs aren't really user friendly. So dealing with them has to be
softened. EasyExtend offers the csttools and cstgen modules. Since
csttools imports cstgen using a from cstgen import*
statement you only ever have to import csttools. Smoothing CSTs will
remain an area of progress also with regard of capabilities provided by
Trail NFAs.
2.2.1 Searching in CSTs
The following considerations are independent of any
particular langlet. If you want you can use just the standard
Python APIs and a
few EasyExtend modules.
from
EasyExtend.langlets.zero.langlet import*
#
the zero langlet is the embedding
#
of standard Python into EasyExtend
#
it is used to support EE tools for
#
Python
from EasyExtend.csttools
import* #
import all kinds of utilities to
#
deal with CSTs
import
parser # the
parser module of Pythons
# standard
library
cst =
parser.expr("foo(x+9)").tolist() #
create a parse tree
pprint(cst) #
special pprint imported from zero
stdout
------
eval_input -- S`258 -- 258
testlist
-- S`326 -- 326
test
-- S`303 -- 303
...
atom -- S`317 -- 317
NAME -- T`1 -- 1
foo
trailer -- S`321 -- 321
LPAR -- T`7 -- 7
(
arglist -- S`329 -- 329
argument -- S`330 -- 330
test -- S`303 -- 303
...
arith_expr -- S`313 -- 313
term -- S`314 -- 314
factor -- S`315 -- 315
power -- S`316 -- 316
atom -- S`317 -- 317
NAME -- T`1 -- 1
x
PLUS -- T`14 -- 14
+
term -- S`314 -- 314
factor -- S`315 -- 315
power -- S`316 -- 316
atom -- S`317 -- 317
NUMBER -- T`2 -- 2
9
RPAR -- T`8 -- 8
)
NEWLINE --
T`4 -- 4
ENDMARKER -- T`0 -- 0
|
Since the CST reflects the grammar structure one has to lookup the
grammar rules in order to keep nodes.
import
symbol
# Imports the symbol module of Pythons stdlib.
n_atom = find_node(cst, symbol.atom)
# Depth first search on cst for a node with
# node id == symbol.atom. Only the first node
# being found is yielded.
pprint(n_atom)
stdout
------
atom --
S`317 -- 317
NAME -- T`1
-- 1
foo
n_atoms = find_all(cst,
symbol.atom)
# finds all nodes of a particular node type
for n_atom in n_atoms:
pprint(n_atom)
stdout
------
atom --
S`317 -- 317
NAME -- T`1
-- 1
foo
atom --
S`317 -- 317
NAME -- T`1
-- 1
x
atom --
S`317 -- 317
NUMBER --
T`2 -- 2
9
|
The search can be constrained. Here another example:
import
token
cst = parser.suite("if test1 == True:\n print 'o.k'\n").tolist()
n_if_stmt = find_node(cst, symbol.if_stmt)
n_test = find_all(n_if_stmt, symbol.test)
for test in n_test:
print unparse(test)
stdout
------
'test1 == True'
'"o.k"'
n_test =
find_all(n_if_stmt, symbol.test, level=1)
# Here is a more constrained version. The
# level parameter determines
the maximum
#
depth to be searched for symbol.test when
# n_if_stmt is the root node
for test in n_test:
print unparse(test)
stdout
------
'test1 == True'
n_test =
find_all(n_if_stmt,
# another variant
using the axis parameter.
symbol.test,
#
find_all does a depth first search for the nid
axis=symbol.if_stmt)
# provided by the axis parameter.
Than it looks
# for all ocurrences of symbol.test in the
found
for test in n_test:
# node
print unparse(test)
stdout
------
'test1 == True'
|
The find_node and find_all functions are the most important search
functions on CSTs. There are few variants
- find_one_of - like
find_node but instead of one node id as a second parameter one passes a
list of node id's.
- find_all_of
- like find_all but instead of one node id as a
second parameter one passes a list of node id's.
2.2.1.1
The find and the get family
We can summarize the desciptions of find_node and find_all.
-
| find_node( |
tree,
node_id, level=10000, exclude=[]) |
- Seeks for one node with id = node_id
in tree. It returns the first
node being found in a depth-first
search or None otherwise.
- The
maximal depth of the searched tree is constrained by level which has a high value by
default. If level is set to 1 only
- the direct subnodes of tree will be inspected. The optional
exclude parameter is a list containing nodes excluded from search. When
e.g. exclude = [ symbol.funcdef ] then find_node does not seek for
node_id in subnodes of funcdef.
-
| find_all( |
tree,
node_id, level=10000, exclude = []) |
- Seeks for all nodes with id = node_id
in tree. It returns the all
nodes being found in a depth-first
search or [] otherwise.
- The
maximal depth of the searched tree is constrained by level which has a high value by
default. If level is set 1 only
- the direct subnodes of tree will be inspected. The optional
exclude parameter is a list containing nodes excluded from
search. When e.g. exclude = [ symbol.funcdef ] then find_node does not
seek for node_id in subnodes of funcdef.
Several variants exist:
-
| find_one_of( |
tree,
node_ids, level=10000, exclude=[]) |
- Like find_node but instead of one node id a list of of node
ids is passed into the function. The first node being found for one of
the node ids is returned.
-
| find_all_of( |
tree,
node_ids, level=10000, exclude = []) |
- Like find_all but instead of one node id a list of of node
ids is passed into the function. All nodes being found for all node ids
are returned.
The functions find_all
and find_all_of
have corresponding generators called find_all_gen
and find_all_of_gen.
After implementing several langlets I realized that the level parameter is used almost
exclusively for searches on level 1. So I decided to implement
convenience functions that isolate this case.
Several variants exist:
-
- Equals find_node(tree,
node_id, level = 1).
-
- Equals find_all(tree,
node_id, level = 1).
etc.
2.2.2 Chain objects
CST nodes have subnodes but are not linked directly to their
parent nodes. In order to climb the node
chain back to the top a Chain object as well as functions
find_node_chain and find_all_chains are introduced. The Chain object
serves as a parental chain for CST nodes. It will be created ad hoc.
Example:
>>> cst =
parser.expr("foo").tolist()
>>> chain = find_node_chain(cst, symbol.atom)
>>> chain
<EasyExtend.csttools.Chain object at 0x013C3A70>
>>> chain.up()
([317, [1, 'foo']], <EasyExtend.csttools.Chain object at
0x013C3B70>)
>>>
chain.step()[1].up()
([316, [317, [1, 'foo']]], <EasyExtend.csttools.Chain object at
0x013C3DB0>)
|
On each up() the found node together with a Chain representing the
parent is returned. To keep each node of the node chain use the
unfold() method of the chain object:
>>> for
node in chain.unfold():
.... print node
[317, [1, 'foo']]
[316, [317, [1, 'foo']]]
[315, [316, [317, [1, 'foo']]]]
[314, [315, [316, [317, [1, 'foo']]]]]
[313, [314, [315, [316, [317, [1, 'foo']]]]]]
[312, [313, [314, [315, [316, [317, [1, 'foo']]]]]]]
[311, [312, [313, [314, [315, [316, [317, [1, 'foo']]]]]]]]
[310, [311, [312, [313, [314, [315, [316, [317, [1, 'foo']]]]]]]]]
[309, [310, [311, [312, [313, [314, [315, [316, [317, [1,
'foo']]]]]]]]]]
[307, [309, [310, [311, [312, [313, [314, [315, [316, [317, [1,
'foo']]]]]]]]]]]
[306, [307, [309, [310, [311, [312, [313, [314, [315, [316, [317, [1,
'foo']]]]]]]]]]]]
[305, [306, [307, [309, [310, [311, [312, [313, [314, [315, [316, [317,
[1, 'foo']]]]]]]]]]]]]
[304, [305, [306, [307, [309, [310, [311, [312, [313, [314, [315, [316,
[317, [1, 'foo']]]]]]]]]]]]]]
[303, [304, [305, [306, [307, [309, [310, [311, [312, [313, [314, [315,
[316, [317, [1, 'foo']]]]]]]]]]]]]]]
[326, [303, [304, [305, [306, [307, [309, [310, [311, [312, [313, [314,
[315, [316, [317, [1, 'foo']]]]]]]]]]]]]]]]
[258, [326, [303, [304, [305, [306, [307, [309, [310, [311, [312, [313,
[314, [315, [316, [317, [1, 'foo']]]]]]]]]]]]]]]], [4, ''], [0, '']]
|
2.2.3 Generic
CST builders
Pythons syntax is medium sized with ~ 80 different grammar rules
and ~ 60 different token. While searching within CSTs is very simple
as illustrated above, synthesizing CSTs isn't. Different
strategies to deal with it but each of them is grounded in the use of
CST builder functions.
EasyExtends structural elegance stems to a large extent from its Trail
parser generator. Trail translates EBNF grammars into finite automata
that can be visualized as syntax diagrams. Those diagrams are now used
to parse languages but their primary and original purpose was to check
syntax. So when you take a set of CST nodes and form a list to create a
new CST, the validity of the CST node in some predefined grammar can be
checked using a syntax diagram created by Trail. But the diagram can
also be used to correct the new CST - at least somewhat - when a node
is missing that can be reconstructed unambigously.
Example: let's keep the repeat_stmt rule again
Grammar.ext
-----------
repeat_stmt: 'repeat' ':' suite
'until' ':' (NEWLINE INDENT test
NEWLINE DEDENT | test NEWLINE )
|
In order to build the corresponding CST from its constituents we need
precisely two CSTs, namely suite and test. When we know the correct
syntax ( and Trail knows it because it can traverse the syntax diagram
) everything else can be inserted. So suppose you have a higher order
function that keeps the node id of the relevant grammar rule ( i.e.
symbol.repeat_stmt ) loads the corresponding syntax diagram and returns
a function that can be used to build the repeat_stmt CST specifically:
repeat_stmt_builder = cst_builder_function(symbol.repeat_stmt)
Now you pass a suite and a test node to repeat_stmt_builder. The
repeat_stmt_builder works in the following simple way:
- A 'repeat' symbol is expected ( in the form of a NAME token
) and a suite is provided. But since 'repeat' can be inserted into the
CST unambigously it is added automatically.
- A colon ':' is expected ( in the form of a COLON token )
and suite is provided. But since COLON can be inserted into the CST
unambigously it is added automatically.
- suite is expected and inserted.
- Proceed with 'until' and the next colon as in 1. and 2.
- Either NEWLINE or test is expected. Since test is provided
insert test.
- After test has been inserted nothing is provided. NEWLINE
is still expected but can be inserted automatically.
2.2.4 CST wrapper
We have just seen that a CST can be completed given just a few grammar
nodes since there are variable and fixed parts in the pattern of a
rule. Now suppose you pass a node of type atom instead of test. The cst
builder finds atom instead of test and fails. But now consider that
test can also be build unambigously from atom.
Grammar
-----------
test:
or_test ['if'
or_test 'else' test] | lambdef
or_test: and_test ('or'
and_test)*
and_test: not_test ('and'
not_test)*
not_test: 'not' not_test | comparison
comparison: expr (comp_op
expr)*
expr: xor_expr ('|' xor_expr)*
xor_expr: and_expr ('^'
and_expr)*
and_expr: shift_expr ('&'
shift_expr)*
shift_expr: arith_expr
(('<<'|'>>') arith_expr)*
arith_expr: term (('+'|'-')
term)*
term: factor
(('*'|'/'|'%'|'//') factor)*
factor: ('+'|'-'|'~') factor | power
power: atom trailer* ['**'
factor]
atom:
('(' [yield_expr|testlist_gexp] ')' |
'[' [listmaker] ']' |
'{' [dictmaker] '}' |
'`' testlist1 '`' |
NAME | NUMBER | STRING+)
|
So we can construct a path from test to an atom A that looks like this:
test_builder(or_test_builder(and_test_builder(not_test_builder(....(power_builder(A)...)))
More generally: we can consider the set of pairs (N1, N2) of node ids
for each N1 != N2 being available from symbol.py and token.py. For each
of those pairs we can say whether we can create an unambigous path
between N1 and N2 in the above manner. Note that this won't define an
order on the set of node id pairs since cycles are allowed in the
grammar. For example: there is a directed path: test -> atom as
demonstrated above but also a directed path atom -> test:
Grammar
-----------
atom: ('('
[yield_expr|testlist_gexp] ')' |
'[' [listmaker] ']' |
'{' [dictmaker] '}' |
'`' testlist1 '`' |
NAME | NUMBER | STRING+)
testlist_gexp:
test ( gen_for |
(',' test)* [','] )
|
For any test node T we can create:
atom_builder(testlist_gexp_builder(T)
This procedure has gotten an own name and is called atomization. We will see later, when we discuss
CST transformations, why atomize is important.
Besides generic wrappers EasyExtend also provides some with specific
targets:
- any_test - wraps CST into test node if
possible
- any_stmt - wraps CST into stmt node if possible
2.2.5
Imitating AST builders - the cstgen module
You won't usually need to use generic cst builder functions directly.
They are very nice as a starting point to build more high level
libraries that better express intent. When you examine the
documentation of Pythons compiler package you will find e.g. an API
description for an AST builder function for function calls:
| CallFunc |
node |
expression for the callee |
|
args |
a list of arguments |
|
star_args |
the extended *-arg value |
|
dstar_args |
the extended **-arg value |
EasyExtend has an own variant of CallFunc, names CST_CallFunc. The API
is similar:
| CST_CallFunc |
name |
this can be a dotted name representing a function
name or method call
|
|
args |
a list of arguments
|
|
star_args |
the extended *-arg value |
|
dstar_args |
the extended **-arg value |
| returns |
|
node of type ( node id )
power
|
The main difference is that CST_CallFunc keeps other CST nodes as
arguments. But it is also possible to pass arguments of type int or str
into the function.
>>> cst =
parser.expr("f(1+2)").tolist()
>>> n_sum = find_node(find_node(cst, symbol.power),
symbol.arith_expr) # extract the sum
>>> func_call = CST_CallFunc("m.foo", [1, "a", n_sum])
>>> unparse(func_call)
'm.foo( 1, a, 1 + 2 )'
|
2.2.6 Top
down CST modifications : macros
Macros or macro like CST transformers having a high level interface
were once introduced with EasyExtend 2.0. Actually macros were the
main motivation to rewrite EasyExtend 1.0 and invent the fiber-space
concept. A macro is a langlet expression used to transform other
langlet expressions. This is done in the way of expanding expressions
of the macro langlet by nodes of the target langlet. Not all
transformations of the target langlet CST might be covered by the macro
langlet though. The target langlet declares a transformer action for
some node N and when being called it passes N into the macro
transformer that yields a macro langlet CSTMacro where the
macro expansion has been applied. Further transformations might apply
on subnodes of N in the same manner. This leads to simultaneous
transformations of macro langlet CSTs and target langlet CSTs. In
particular CST nodes belonging to different langlets are mixed in one
CST.
2.2.6.1 exo.space
However the macro
implementation was very complex, never particular robust and has
finally been dropped from EE 3.0. The complexity was partly due to the
circumstance that currently each expression created on transformation time
has to be re-encoded and integrated as a CST. There is no
persistence layer other than the bytecode compiled pyc file. In
EasyExtend 3.0 a persistence framework is included called exo.space.
The exo.space layer contains pickled objects created during CST
transformation. The langlet code can refer to exo.space
objects using
named or generated references.
Unlike EasyExtend 2.0
where the macro code was defined in the node transformers of the target
langlet the macros might now be defined in own macro definition modules
with the specific suffix pymc.
When those pymc modules
are compiled CST transformer functions representing those macros are
generated but they are not backtranslated into CSTs but pickled into an
exo.space. The pyc module
of the corresponding pymc
module only contains compiled stubs. They delegate calls to exo.space
function objects that get unpickled and cached on demand. This feature
is planned for EasyExtend 3.1.
3. Langlets
Langlets
are the new EE 2.0 fibers.
Renaming things is painful but there were indications of an increasing
use the term fiber in
concurrency ( otherwise named as green threads, microthreads etc. ). I
surrendered.
So far the Java community has not occupied langlets nor is it otherwise
overcrowded by trivial and redundent use. It's free and I think it's
closer in meaning than the original wording.
|
 |
3.1 Some guiding
images
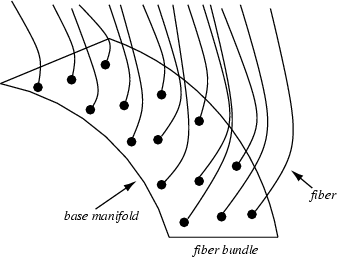
Divine snakes and hairy fiber-bundles. A taste of allegory - Python as
the base manifold, langlets as fibers and EasyExtend as the tool used
to construct fiber spaces.
3.2 The fiber-space
There are still residuals of the old story. When you inspect EEs
source files you'll find modules like fstools.py, fs.py or even fslanglet.py. EasyExtend is
characterized by supportive prefixes. ee
and cst are just too obvious. nfa is used by Trail and fs is for fiberspace. ee cst nfa fs - what's left to say?
Maybe lex and parse?
You might have already understood that EasyExtend is about defining
transformations CSTExt -> CSTPy.
What if you use one langlet to transform another one? I
strived the idea briefly in my remarks about macros. In that case
you have a langlet L1
which takes nodes of a langlet L2 as
arguments. An L1
node transformer produces a new L1 node
containing alsoL2nodes.
So the resulting CST mixes nodes of different langlets. In order to
discern them and bind transformer actions to node ids unambigously the
node ids of different langlets must be disjoint sets. With this
requirement all nodes of the CST of L1 + L2 can
be transformed simultanously. Finally it shall
be nevertheless simple to map the CSTL1 + L2
onto CSTPy.
3.2.1 Ranges and
offsets
The
solution is to partition the natural numbers into intervals of length
512 and create a unique offset k*512 with k = 0, 1, 2,... for each
langlet. Remind that Python partitions the interval [0, 512) and
reserves [0,255] for token / terminal node ids and [256,512) for
non-terminals. This partition shall be preserved for different offsets
K:
[K, K+255]
- node ids for langlet
terminals
[K+256, K+512) - node ids for langlet
non-terminals
When a new langlet is created a file called fs is opened. The fs file contains a single
number called offset_cnt.
This offset_cnt will
be incremented and re-inscribed into fs. Using offset_cnt a new
LANGLET_OFFSET = 512*offset_cnt
is built. You'll find the number in the conf.py file of your langlet
but also in lex_token.py.
########################################################################
#
#
Language configuration
#
########################################################################
# --- unique langlet offset ---
# Warning! do not touch this. It will be automatically generated by
fs.py
LANGLET_OFFSET = 3584
# modules and functions
import os
import sys
...
|
It
might be questionable that this range splitting is sufficient for
arbitrary languages and large grammars can be encoded. So far I do
think it can encode COBOL
but not much larger programming languages than that ( Note that
arbitrary many keywords can be
used ). So if you intend to create a
COBOL langlet and simulate COBOL on CPython EasyExtend will be an
appropriate tool for this job.
3.2.2 Projections
The node ids of
a langlet are meaningless to the Python compiler. The compiler does not
know how deal with a node id 3840. Before EE can compile a
langlet CSTExt it
has to projected onto
a CSTPy. This projection is very simple. We just take
the rest of a langlet node id value by division of 512 :
nidExt % 512 = nidPy
projection
CSTExt
-------------> CSTPy
Another number is MAX_PY_SYMBOL
which is defined in
cst.py,
MAX_PY_SYMBOL = 339 # maximal node_id of Python
2.5 symbol range
This number is the maximum node id found in Pythons
symbol.py and is release specific. For example Python 2.5 defines some
new grammar rules not implemented in Python 2.4 and its MAX_PY_SYMBOL
is 339. If projection(CSTExt)
contains node ids exceeding MAX_PY_SYMBOL
this is a safe indication that the transformation has not
been finished yet.
3.2.3
Simultaneous transformations
Each langlet defines a LangletTransformer
class in langlet.py.
This class defines actions which are called when a node with a certain
node id is visited in the CST. We will talk later about details of the
Transformer classes. When a CST shall be transformed the corresponding
transformer instance of the LangletTransformer
is called as
transformer.run(
cst )
But what is there isn't just one relevant transformer instance? The
solution is such that the transformer
instances are registered at a
singleton fs_transformer
instance of a more general FSTransformer.
The fs_transformer dispatches
all node actions to the correct transformer; actually it extracts
transformer methods from all registered transformers and dispatches
nodes to them. So in the background there is always a unique
meta-transformer that handles all actions of active langlets.
3.3 Using zero
The EasyExtend distribution contains the important zero
langlet.The zero langlet
doesn't contain own grammar or token definitions. It is a blank langlet
or some kind of Python being embedded in the fiberspace. Whenever you
want to inspect Python code using csttools
you can use zero
as some
default langlet in functions that require one. Take for example this
simple script for accessing all function names in a Python module.
import
EasyExtend.langlets.zero.langlet as langlet
from EasyExtend.csttools import*
import sys
if __name__ == '__main__':
module = sys.argv[1]
source = open(module).read()
cst = langlet.parse(source)
func_nodes = find_all(cst, langlet.symbol.funcdef)
print "--- function names found in module
`%s` ----"% module
for f in func_nodes:
names = find_all(f,
langlet.token.NAME, level = 1)
print
names[1][1] # names[0][1] is aways 'def'
|
You can eternally refine this script.
Not many checks are needed here since the nodes are always structured
in the same way. However a funcdef node can have an optional decorators
subnode preceeding 'def'.
So using find_all on NAME together with a level inormation that
prevents searching within an optional decorators node is a safe deal.
Alternatively one can check for a decorators subnode initially
print "--- function names found in module
`%s` ----"% module
for f in func_nodes:
if is_node(f[1],
langlet.symbol.decorators):
print
f[3][1]
else:
print
f[2][1]
|
I think the most beautiful property of these kinds of scripts is that
they apply to all langlets in a uniform way that extend Python
conservatively i.e. don't modify the the funcdef
node. If the content of
the if __name__ == '__main__' block is factored into a function keeping
a langlet as a parameter it can be applied also on gallery. This gives
rise to the idea of abstracting over languages and providing langlet
interfaces or langlet types.
4 The framework
4.1 The
langlet.py and conf.py modules
The langlet.py module
is the basic ground where langlet specific definitions are
inserted. When created a langlet.py
module contains a bunch of classes that might be overwritten.
from
conf import*
from csttools import*
class
LangletTokenizer(eetokenizer.Tokenizer):
'''
Langlet specific tokenizer settings and
definitions.
'''
class LangletImporter(eeimporter.Importer):
'''
Langlet specific import settings
'''
class LangletTransformer(eetransformer.Transformer):
'''
Defines langlet specific transformations
'''
|
The relevant classes Tokenizer,
Importer and Transformer
are already imported with conf.py.
You can consider conf.py
as an extension of langlet.py. Usually doesn't have to be
changed once a langlet is created. Some changes ( that of the LANGLET_OFFSET
specifically )
might even cause inconsistencies. So conf.py
is somewhat like the
static part of the langlet. The conf.py
module contains objects
being configured with the defining langlet. So you will find functions
like
pprint,
unparse, parse
and tokenize
which are
langlet specific. Calling
langlet.parse(
"1+2\n" )
parses the statement "1+2\n" into a langlet specific CST and
langlet.pprint( langlet.parse( "1+2\n" ) )
will display it.
4.2
LangletTransformer
The
LangletTransformer class is the most important one of the three classes
you have seen above. Actually the LangletTokenizer and the
LangletImporter classes can be deleted if not needed. Not so the
LangletTransformer. The LangletTransformer binds actions to node ids
using a set of correspondences.
Suppose you want to transform the node corresponding to the repeat_stmt
grammar rule in
Grammar.ext ( or while_stmt
in Grammar ... ). The name of the rule is unambigously defined for the
langlet. The following code shows how to make the node action public.
class LangletTransformer(eetransformer.Transformer):
'''
Defines langlet specific transformations
'''
@transform
def repeat_stmt(self, node, **kwd):
"""
repeat_stmt: 'repeat' ':' suite 'until' ':'
(NEWLINE INDENT test NEWLINE DEDENT |
test NEWLINE )
"""
|
Without the @transform
decorator the repeat_stmt
action wasn't recognized as a node transformer actions and not
executed. Writing the grammar rule into the comment string is a
convention. It helps the author of the tranformation and the reader of
the code. It is by no means signficant and you can omit it.
The result of the action can be
- A single CST node N of arbitrary node id
- A list of CST nodes L of CST nodes having the same node id
- None
When you output a single CST node N the LangletTransformer
instance
will try to substitute the input repeat_stmt
CST node using N.
This is most usually not a
direct substitution. In case of repeat_stmt
this wouldn't make
any sense when the target is a CSTPy.
When you inspect the CST in detail containing a repeat_stmt
it will have the
following structure:
[file_input,
[stmt, [compound_stmt, [repeat_stmt, [...]]], ...]
Suppose N is a node of type stmt.
Then the transformer will iteratively check the parents and
grandparents etc. for being a node of type stmt
as well. This node will be substituted. Just slightly more complicated
is the situation when the transformation rule returns a list L of nodes
of type stmt.
Again
the node hierarchy will be climbed up to find the first node of
type stmt
but
this time stmt is not substituted by L but L has to be expanded
within the parent of the stmt node
to be subsituted:
L = [[stmt,[...]], [stmt,[...]]]
v
[file_input,
[stmt,[...]], [stmt,[...]], [stmt,[...]]]
======>
[file_input,
[stmt,[...]], [stmt,[...]], [stmt,[...]],
[stmt,[...]]]
4.2.1
any_expr, any_test, any_stmt
Suppose
you want to substitute the repeat statement by a while statement in the
final Python version. The corresponding target node is while_stmt.
But while_stmt does
not exist in the original node hierarchy. Direct substitution of repeat_stmt
by while_stmt will
fail. You'll
have to wrap the
node into another node which is somewhere placed in the node
hierarchy. There are four kinds of nodes that play a favourite role:
| |
stmt |
top level node for all kinds of statements |
|
test |
top level node for all kinds of expressions |
|
expr |
top level node for many expressions but does not
contain predicates ( a or b
, not a, ...)
comparisons (
a>b , a == b, ...) and lambda
forms. |
|
atom |
contains over names, numbers, strings, lists, tuples
and dicts, expressions in parens |
When you have an arbitrary statement node S like while_stmt
or raise_stmt
then any_stmt(S)
will return a stmt node.
Same with the any_test wrapper
and nodes like and_test
and atom.
Below you can see a wrapping table for Python 2.5.
| any_stmt |
stmt, simple_stmt,
compound_stmt, small_stmt, if_stmt, for_stmt, while_stmt, try_stmt, with_stmt, break_stmt,
continue_stmt, return_stmt, raise_stmt, yield_stmt,
expr_stmt, print_stmt, del_stmt, pass_stmt, flow_stmt, import_stmt,
global_stmt, exec_stmt, assert_stmt |
| any_test |
test, and_test,
or_test, lambdef, not_test, comparison, expr, yield_expr, xor_expr,
and_expr, shift_expr,
arith_expr, term, factor, power, atom |
| any_expr |
expr, yield_expr, xor_expr,
and_expr, shift_expr,
arith_expr, term, factor, power, atom |
4.2.2 atomization
Each of the any_N
wrapper functions takes a node that is placed lower in the node
hierarchy and returns a node N that is higher in the hierarchy
according to the substitution algorithm of the LangletTransformer.
But
sometimes we need it the other way round and instead of a node
being in the hierarchy we want one that is lower.
Assume you have a CST corresponding to the expression "a+b" and you want to
substitute `a` by `c*d`. Wrapping just `c*d` into expr or test
won't work because the expression `a+b` would be entirely substituted
in the node hierarchy instead of the single term `a`. The
solution to this problem is to wrap the CST of `c*d` into an atom node.
This procedure is called atomization
and the corresponding function is called atomize. When you unparse the
atomized `c*d` CST the resulting source code is `(c*d)`. So atomize
inserts just parens!
Now the `(c*d)` atom can substitute `a` in `a+b` using the usual
substitution algorithm.
4.2.3 Node markers
Up to version 3.0 EasyExtend had a serious problem with re-insertions
of nodes during transformations.
Suppose you have defined a transformer action for nodes of type atom
and another one for nodes
of type and_test.
The and_test
transformer will
produce a new node containing new symbols. This node will likely
contain also an atom subnode
which will be transformed after further CST inspections. If everything
goes bad atom will return
a node of type test and
the and_test subnode will be called again: we have produced an infinite
transformion loop.
To
prevent this behaviour once and for all each node in the original CST
is tagged initially. Since the node transformers are known initially
all corresponding nodes will be tagged in a preparation step. Later
when the node is visited the tag value will be changed from False to True.
In no way will this node be revisited. Moreover new nodes produced
within transformer actions will not be tagged. So they won't be
transformed accidentally. You can modify this behaviour by explicitely
tagging them using the mark_node
method of the LangletTransformer
but you are doing it on your own risk.
4.2.4
Special transformations
4.2.4.1
How is it to
be
__like_main__ ?
Running a langlet specific module mod.gal
from the command line has following form
python run_gallery.py mod.gal
The problem with this command line is that the __main__ module is run_gallery.py
but not mod.gal!
As a
consequence canonical execution blocks
__name__
== '__main__':
BLOCK
will always be ignored in mod.gal. But since the module object mod.gal
is passed into a function called by run_gallery we can call a function
instead that contains the code that executes the code block of __name__ ==
'__main__'.
This function is called __like_main__.
Before __like_main__ can be called the following code transformation
has to be applied in mod.gal
:
|
if __name__ ==
__main__:
BLOCK |
==>
|
def __like_main__():
BLOCK
if __name__ == '__main__':
__like_main__()
|
The __name__
== '__main__'
block is reproduced here. This is for purposes when you run the
compiled module mod.pyc
in the command line form:
python mod.pyc
4.2.4.2
__publish__ or perish
Other than the basic CPython interpreter langlets don't have a shared
__builtin__ namespace being available for all langlet modules. The
__publish__ list as a compensation is used to define those langlet
names being added to the builtins. It is only a list of names not a
dictionary. As a dictionary langlet.__dict__ is used. However not all
names in langlet.__dict__ shall become builtin but usually just two or
three. There is no syntactical transformation asociated with
__publish__.
4.2.4.3
import __langlet__
When a langlet module mod.gal
is compiled to the bytecode module mod.pyc
and the mod.pyc
is
executed on the command line as
python mod.pyc
no langlet names will be available and the module is likely broken. To
adjust this for each module an import statement is generated it looks
like
import
EasyExtend.langlets.<langlet_name>.langlet as __langlet__
import EasyExtend.eecommon;
EasyExtend.eecommon.init_langlet(__langlet__)
4.3 LangletImporter
With
EasyExtend 3.0 import policies have been greatly simplified since
EasyExtend supports new proper file suffixes. So once you have defined
a file suffix e.g. gal
for gallery langlet modules. Those suffixes will be recognized by the
LangletImporter and the module will be imported correctly.
The exceptional cases are now those where the langlets preserve the py suffix. The inverse default
policy applies here: EasyExtends transformer machinery will never be applied. Instead the
modules are compiled as normal Python modules.
So when you intend to change or extend policies for importing Python
modules regarding your langlet you have to overwrite the accept_module
method defined in eeimporter.py.
class
LangletImporter(eeimporter.Importer):
'''
Langlet specific import settings
'''
def accept_module(self, mod_name):
return self # accepts each
module everywhere
|
 |
Even if you set free each module for import there
will be a list of EasyExtend framework modules that will never be affected by accept_module
and will always only imported by Python. These are addressed in
pre_filter and no_import.
|
As an example you might look at the coverage langlet implementation.
The coverage langlet enhances acceptance filtering because not all
modules being found on import shall actually be covered.
4.4 LangletTokenizer
For all convenient extension language purposes but for many other
langlets as well you don't have to care about this class.
Lexing
is a two phase pass in EasyExtend. First the system produces a basic
token stream using a Token and Token.ext file based on the nfalexer.
Then it passes the token stream to a post-processor for context
sensitive operations. The main purposes of the post-processor is to
deal with INTRON
token objects.INTRON
token
contain whitespace and comments. These are usually denotated by more
pejorative names like IGNORE
or JUNK.
In Python however there is nothing more significant and less ignorable
than whitespace and the Tokenizer base class of LangletTokenizer will
create new token of the kind NEWLINE,
INDENT and DEDENT
from token. So if you want to change this machinery you might overwrite
( or
add ) methods defined in the Tokenizer class of eetokenizer.py.
The way token actions are handled are very similar to those of the
LangletTransformer.
class LangletTokenizer(eetokenizer.Tokenizer):
'''
Defines tokenizer specific transformations
'''
@post
def INTRON(self, node):
"INTRON: COMMENT | (WHITE [COMMENT])+ |
LINECONT "
# produces INDENT, DEDENT and NEWLINE token
and handle line continuations
# by inspection of
whitespace, comments and lineconts
|
Currently there is only a single canonical implementation of post
processing token streams in eetokenizer.py.
For implementing variants you might have to take a look there.
5. Tools
5.1 The console
is your friend
The eeconsole
module shall be mentioned just briefly. From a usability point of view
this one is the best piece: once you defined your new Grammar / Token
you can immediately check them out on an interactive prompt. The EEConsole
object defined within eeconsole is
a somewhat redesigned version of Pythons InteractiveConsole
object. It does not only have to deal with incomplete commands but it
needs to transform langlet statements on the fly into a sequence
of Python statements. The interactive console requires unparsing using the cst2source
module. It is not
possible to pass a CST to the compiler in an interactive session but
only source. Although this doesn't harm the user in any way script
compilation continues to use CST compilation in EasyExtend and there
can be errors not detected within an interactive session because
unparsing also smoothes differences in CSTs structures.
5.1.1
Launching a langlet specific
console
A prompt
variable can be either defined on langlet creation or later in the conf.py
module. This variable is accessed by the EEConsole
and the value replaces the standard prompt sys.ps1.
The second prompt sys.ps2
will
be determined as a dotted line whose length corresponds with that of sys.ps1.
Starting
the gallery
console under
Windows may look like:
c:\lang\Python25\Lib\site-packages\EasyExtend\langlets\gallery>python
run_gallery.py
___________________________________________________________________________________
gallery
Running on Python 2.5.1 (#69, Mar 29 2006, 17:35:34) [MSC
v.1310
32 bit (Intel)]
___________________________________________________________________________________
gal> x
= 0
gal> repeat:
.... x+=1
.... print x
.... until: x==3
....
1
2
3
gal> quit
___________________________________________________________________________________
|
Note that you can quit
the console by typing just quit.
You don't get schooled by EEConsole
to use the function call quit()
although the console already knows that you want to quit.
Enriched variants of EEConsole
objects are discussed in the ConsoleTest
tutorial.
5.2 Debugging with
pdb
Debugging using the pdb module
should work as convenient but don't forget to pass globals()
explicitely into pdb.run().
Example: Using module gallery.test.funcs
and function
def f_repeat_until(x):
repeat:
x-=1
until:
x<7
return x
we get the following session trace on the Gallery console:
gal> import gallery.tests.funcs
as
funcs
gal> import pdb
gal> pdb.run("funcs.f_repeat_until(7.5)",globals())
> <string>(1)?()
(Pdb) s
--Call--
> c:\python24\lang\gallery\test\funcs.py(6)f_repeat_until()
->
(Pdb) n
> c:\python24\lang\gallery\test\funcs.py(8)f_repeat_until()
-> repeat:
(Pdb) n
> c:\python24\lang\gallery\test\funcs.py(9)f_repeat_until()
-> x-=1
(Pdb) n
> c:\python24\lang\gallery\test\funcs.py(10)f_repeat_until()
-> until:
(Pdb) n
> c:\python24\lang\gallery\test\funcs.py(12)f_repeat_until()
-> return x
(Pdb) n
> c:\python24\lang\gallery\test\funcs.py(266)f_repeat_until()
(Pdb) n
--Return--
> c:\python24\lang\gallery\test\funcs.py(266)f_repeat_until()->6.5
(Pdb) n
--Return--
> <string>(1)?()->None
(Pdb) n
gal>
|
5.3 Command line
options
Command line option
|
Description
|
| -h, --help |
show this help message and
exit
|
| -b, --show_cst_before |
show CST before transformation |
| -a, --show_cst_after |
show CST after transformation |
| -m SHOW_MARKED_NODE,
--show_marked_node=SHOW_MARKED_NODE |
mark one or more different kind of nodes in CST |
| -p,
--show_python |
show translated
Python code |
| -t,
--show_token |
show filtered token
stream being sent to the parser |
| -v,
--cst-validation |
CST validation
against Python grammar |
--show-scan
|
show unfiltered
token stream being sent into the lexical post processor
|
| --re-compile |
re compilation even
if *.pyc is newer than source |
| --parse-only |
terminate after
parsing
file |
--full-cst
|
display expanded cst
|
--rec
option
|
use recording
console to
record interactive session
( see ConsoleTest )
|
| --rep=SESSION |
replays an
interactive
session
( see ConsoleTest )
|
| --full-cst |
display complete
CST ( without possible omissions )
|
| --dbg-lexer |
displays debug
information
for lexer run |
--dbg-parser
|
displays debug
information for parser run |
| --dbg-import |
displays debug
information for importer
|
5.4 t_dbg
minicommands
A useful aid to track single node
transformations is the decorator
@t_dbg. @t_dbg can be used together with @transform. t_dbg is kind of a
tiny command interpreter used to check conditions on individual nodes
passed to node transformers and display content. A variant of @t_dbg is
the @transform_dbg decorator. It unifies the functionality of @t_dbg
and @transform. I originally introduced only @transform_dbg but more
often than not I uncommented the whole decorator when I intended to
deactivate tracking functionality.
-
| t_dbg( |
spec,
cond = None, **kwd) |
- spec:
specifier string. A specifier string is a list of commands specifiers
e.g. "ni
no co gc". Each command
specifier is two letters long.
Command specififiers can be chained arbitrarily with or without
demlimiters.
-
The sequence by which the commands are executed, if available, is fixed.
If you use
delimiters use whitespace, colons, commas or semicolons.
- cond:
predicate. If cond predicate is available commands will only be
executed when the
input data have passed
the cond filter. cond has the signature cond(node, **locals).
- kwd:
a dictionary specifying user defined actions. The keys of the dict are
command
Command
|
Description
|
| ni |
display plain node (input) |
| no |
display plain node(s) (output) |
| ci |
display input CST |
| co |
display output CSTs |
cv
|
CST validation. If
no output node is produced assume that input node is modified inplace
and check input node after transformation.
|
| ca |
display input CST after transformation. Used
when input node is modified inplace and no output
node is produced. |
so
|
unparsed python
source output |
si
|
unparsed python
source input
|
sa
|
unparsed python
source of input node after
transformation. Used when input node is modified inplace and no output
node is produced.
|
r1
|
check that result
is a single node
|
r>
|
check that result
is a list of nodes
|
r=
|
check that result
node ids equals input node id
|
r!
|
check that result
node ids not equals input node id
|
fi
|
arbitrary test
function of one argument executed on node input
|
fo
|
arbitrary test
function of one argument executed on node list output
|
Output
Output is formatted like
[si
-- python source (input) -- and_test:584>
a
<si -- python source (input) -- and_test:584]
[cv -- cst validation test -- and_test:584>
CST o.k
<cv -- cst validation test -- and_test:584]
[si -- python source (input) -- and_test:632>
not ( b and True )
<si -- python source (input) -- and_test:632]
[si -- python source (input) -- and_test:728>
b and True
<si -- python source (input) -- and_test:728]
[cv -- cst validation test -- and_test:728>
CST o.k
<cv -- cst validation test -- and_test:728]
[cv -- cst validation test -- and_test:632>
CST o.k
<cv -- cst validation test -- and_test:632] |
The trailing numbers are references to the nodes passed into the node
transformers. The values are arbitrary. They serve the single purpose
of grouping the messages according to nodes. You might notice that in
the trace displayed above the and_test:728
block resides within the and_test:632
block.
Examples:
class LangletTransformer(Transformer):
@transform_dbg("ni cv r1")
def expr(self, node):
...
@transform_dbg("r>soco")
def test(self, node):
...
def raises(ln):
if ln>1:
raise ValueError("Only one output argument expected")
@transform_dbg("r1,co", 'r1' = raises)
def stmt(self, node):
...
@transform
@t_dbg("sn si", cond = lambda node, **locals:
locals.get("line",-1)>=0)
def and_test(self, node, line = -1, idx = 0):
...
|
6.
Discussion
6.1 Caveats
- lnotab. Some code
transformations confuse line recovery.
The creation of
the line-number-table ( lnotab ) is based on constraints that can be
violated occasionally ( monotonicity violation ). This problem affects
any kind of code generator for CPython not only that of EasyExtend. As
a consequence line number information is not reliable and sometimes the
runtime reports completely bogus line number references for
some exception. The deeper cause is that the ( Python 2.4 ) compiler
uses a mixture of line number inormation provided by the parser in the
parse tree and own reconstruction rules that apply while
bytecode compilation. All this is feeded into a very clever and dense
encoding
scheme of lnotab that assigns line numbers to bytecodes. This problem
is rather serious and the only known workaround is to unparse the
transformed CST into Python source code and debug this one.
- Speed !!!. I was
surprised that the new tokenizer was rather slow when tokenizing
Python. It wasn't surprising that it was slow
compared to the formerly used C and regular expression based tokenizer
but
compared to the Trail based parser that uses almost the same algorithm.
The reason for this behaviour is the size of the transition tables for expanded NFAs. Since
Pythons Grammar is LL(1) none of its NFAs is expanded. The complexity
of Trail depends on the numbers and sizes of transition tables. Without
them Trail conforms to an ordinary LL(1) parser. Unfortunately the
biggest
tables in
case of the default tokenizer are also top-level ones with very high
relevance. The worst case is also the most likely one. This already
caused the introduction of two pivotal token which lead to more than
50% speedup. I consider a reimplementation of
Trail in C++ with a C interface and ctypes bindings but unlikely before
the Python prototype has been stabilized and tuned.
- Remark ( EE 3.0 beta2 ): Trail scans ~9,000 chars/s on my
1.5 GHz notebook. 9.000 chars are about 220-250 LOC including
comments. This value already reflects usage of Psyco.
6.2 TODO now!
- More consoletests. More bugfixes.
6.3 Beyond EasyExtend
3.0
Plans for EasyExtend 3.1 ( summer 2008? / Europython 2008 ? ):
- exospace becomes an active transformation time persistence
mechanism
- macro langlet based on exospace persistence will be
reintegrated
- New features in Gallery and coverage
- Trail optimizations. Reimplementation of the relevant
parsing/tokenization algorithms in C++.
- The status of cst.py
is not yet clear. Since all currently available CST functions will be
generated I see little use in seperating cst.py and cstdexx.py. I'm not
sure about dropping them entirely and just throwing the functionality
into csttools.py. The module is quite big altready so it might not be a
good idea.
Plans for EasyExtend beyond 3.1 ( open ended )
- Using enhanced grammar rules that enable specifications of
exact numbers of repetitions.
- Use grammar_langlet to define grammars interactively
- After the cst-builder functions in the cst.py module have
become obsolete in 3.1 I consider also making manually crafted AST
shaped wrappers in cstgen.py obsolete and use a more declarative
approach for wrapper generation. Looks like another attempt for a new
langlet and a call for more Trail.
|